Python Concurrency Part 1 - Multiprocesing
Note for parallel processing
- Why is Pyhon so slow?
- Global Interpreter Lock (GIL)
- Multiprocessing and Threading
- Python Multiprocessing
Why is Pyhon so slow?
With the background in Machine Learning, the natural choice of programming language for me was Python, which was (and still is) overwhelming popular, and the most dominant language in the field of Machine Learning. I have already spent years programming in Python, and I really love the Zen of Python. Like any other programming languages, however, Python is not perfect. Python is innately slower than modern compiled languages like Go, Rust, and C/C++, because it sacrified speed for easier usage and more readable code. But why is it slow exactly?
Common characteristics of Python are:
- Interpreted language
- Dynamically typed
- GC Enabled Language
If you ever studied languages like C++, you know of course that compiled languages have characteristics exactly opposite of above. C compilers like GNU will convert the source code into Machine Code, and generates executables that gets directly ran by CPU. Python, on the other hand, does not provide this compile step. The source code gets executed directly, at which Python will compile the source code into bytecode that can be read by Interpreters, where bytecode instructions are executed on a Virtual Machine, line by line. It can only be executed line by line because the language is dynamically typed. Because we don’t specify the type of a variable beforehand, we have to wait for the actual value in order to determine whether what we’re trying to do is actually legal. These errors cannot be caught during compile time, because the validity can only be checked by the Interpreter.
When learning C/C++, something that always makes you bang your head on the wall is the memory management–Notorious Segmentation Fault Error. Python has automatic garbage collecting, so you never have to worry about things like pointers, but it’s definitely not the most efficient way to handle memory. You can never shoot yourself in the foot, but it slows you down at the same time.
Global Interpreter Lock (GIL)
Another factor that slows Python down is Global Interpreter Lock (GIL). By design, Python operates on single-thread, on a single CPU. Since the GIL allows only one thread to execute at a time even in a multi-threaded architecture with more than one CPU core, you may wonder why in the world that Python Developers created this feature.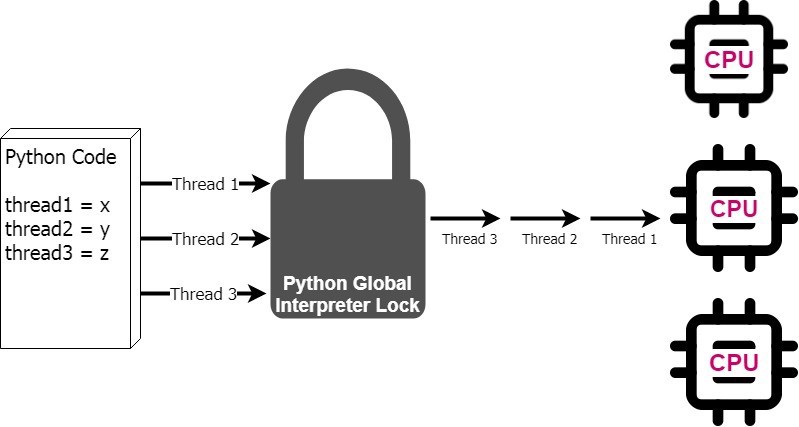
GIL solves a race-condition where multiple threads try to access and modify a single point of memory, which causes memory leak and also sorts of bugs that Python cannot handle. This was practical solution as Python manages memory for you, and earlier Python did not even have the concept of threading.
Languages like Rust guarantees thread safety (no multiple threads accessing same variables at the same time) using similar concepts for memory safety and provides standard library features like channels, mutex, and ARC (Atomically Reference Counted) pointers. Python’s GIL does not gaurantee thread-safety, obviously because it’s making one thread take all the resources. So is there concept of multi-threading in Python? yes of course. This will be discussed in the next section.
Multiprocessing and Threading
In the previous few sections I have discussed the limitations of Python. Some of these problems are simply impossible to overcome due to the nature of Python, but Python has made continuous improvements in many areas and thus it stands where it is right now. Many popular Python packages (and pretty much all ML libraries) are written in C to offer competitive speed, and now Python supports libraries for multi-processing and threading, which gives additional boost to the speed. This blog post will introduce various aspects of multi-processing and multi-threading.
Many people misleadingly use multiprocessing and threading interchangeably, whereas there are not actually the same.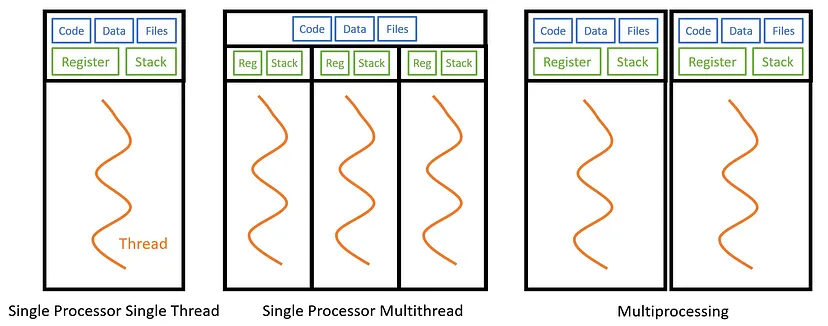
Above illustration is a very nice overview of the difference b/w threading and multiprocessing.
First of all, threading is a great way to speed up application to tackle I/O bound problems, where threads within a single process run parallely. For example, say you have a multi-stage pipeline in your application where user interacts with the server. If there is a significant bottleneck in one of the stages, and your process is only running sequentially, it will take much longer time to finish all the process since the bottleneck process needs to be completed before moving on to the next stage. However, if the process is running concurrently, the entire application should not take much longer than the time required to execute the bottleneck process.
This is why we have Multi-processors. When the program is CPU intensive and doesn’t have to do any IO or user interaction, you can use multiprocessors to exponentially speed up the computation by breaking down the problem into chunks, and delegating each cores to handle the chunks. More processes can be created if your computer has more cores. It becomes less scalable when your spin up more processes than the number of cores in your computer.
Python Multiprocessing
Now that we have covered the basics, it’s time to dive in. In this post, I will cover multiprocessing library, which is the core Python modules for multiprocessing. I have already used multiprocessing to some extent for work (for database migration), so it would be easier to start from something that I am familiar with. Multiprocessing library offers four major parts:
- Process
- Locks
- Queues
- Pools
Process
Process is the most basic unit of execution in Python. Every process has its copy of the Python interpreter and its memory space, allowing multiple jobs to get executed simultaneously without conflicts. There are two types of processes:
Parent Process: The main process that can start another child process.Child process: Process created by another process. Also called subprocess. It can only have one parent process, like how humans can only have one biological paraents. A child process may become orphaned if the parent process gets terminated.
The multiprocessing.Process instance then provides a Python-based reference to this underlying native process. Let’s try creating two processes that starts a function that sleeps.
import time
import multiprocessing as mp
def sleep(sleep_sec=1):
process = mp.current_process()
pid = process.pid
print(f'process {pid}: Sleeping for {sleep_sec} seconds \n')
time.sleep(sleep_sec)
print(f'process {pid} Finished sleeping \n')
# create two process
start_time = time.perf_counter()
p1 = mp.Process(target=sleep)
p2 = mp.Process(target=sleep)
# Starts both processes
p1.start()
p2.start()
# start both process
finish_time = time.perf_counter()
# This must be called from the parent process
if mp.current_process().name == 'MainProcess':
print(f"Program finished in {(finish_time - start_time):.3f} seconds")
But if you look at the output, you will notice that it is a bit funny. One would expect print(sleep) and print(finish) to execute first before the final “Program finished” call to be made on the Parent Process. But instead, you get:
process 2354: Sleeping for 1 seconds
Program finished in 0.006 seconds
process 2357: Sleeping for 1 seconds
process 2354 Finished sleeping
process 2357 Finished sleeping
Why is this happening?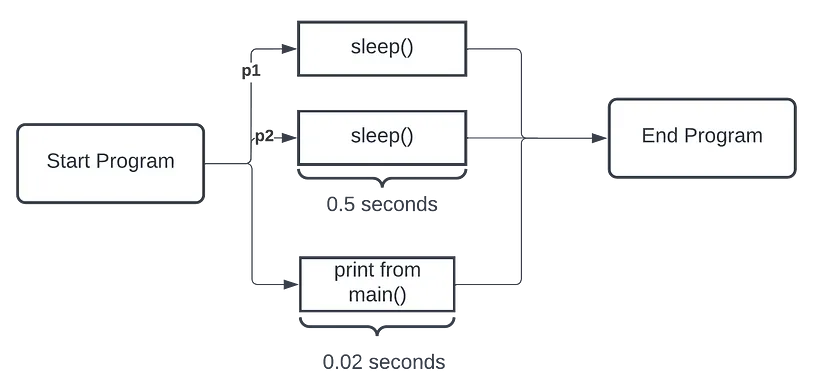
Yes, it’s because the processes are executed without joining, so the main process that only takes 0.02 seconds to execute finished before waiting for p1 and p2 to finish it’s parts. So if you fix this up,
import time
import multiprocessing as mp
# create two process
start_time = time.perf_counter()
# save all the process in a list
processes = []
#create 10 processes that all sleeps
for i in range(3):
p = mp.Process(target=sleep)
p.start()
processes.append(p)
#join all the process
for p in processes:
p.join()
finish_time = time.perf_counter()
# This must be called from the parent process
if mp.current_process().name == 'MainProcess':
print(f"Program finished in {(finish_time - start_time):.3f} seconds")
And now you properly get:
process 6950: Sleeping for 1 seconds
process 6953: Sleeping for 1 seconds
process 6958: Sleeping for 1 seconds
process 6950 Finished sleeping
process 6953 Finished sleeping
process 6958 Finished sleeping
Program finished in 1.017 second
Okay, now we understand how Process are started and joined. But one thing to note, is that there are actually 3 different methods for start.
Spawn: Start a new Python Processfork: Copy a Python process from existing processforkserver: A new process from which future forked processes will be copied.
You can set specific start method like
if __name__ == '__main__':
# set the start method
multiprocessing.set_start_method('spawn')
This isn’t too important for now, so further details are not going to be discussed.
Locks
Next up is the Lock. We learned that process is encapsulated Python program. These processes often share data or resources, and mutual exlcusion lock (Mutex) protects shared resources and prevents race conditions, as race conditions can easily corrupt data and create unwated results. Lock ensures that data is consistent b/w jobs, by preventing another process from accessing the data until the its released.
Let’s look into multiprocessing.Lock class. There are two states: Locked and Unlocked
# create a lock
lock = multiprocessing.Lock()
# acquire the lock
lock.acquire()
# release the lock
lock.release()
Lock is more useuful with the queues. So let’s discuss queues now.
Queues
This is the same queue in the context of data structure. But here we are specifically referring to a first-in, first out FIFO queue, in the context of multiprocessing. Data can be placed to a queue, and processed by another processor when it becomes available, allowing us to break up tasks into smaller parts that can be processed simultaneously.