Networking part 1 - Networking Top Down Approach
Basics of networking (overview)
This is the first part of the networking series.
While studying the basics of networking while educating myself regarding SSH, I discovered that there are much more underlying contents related to it that I must know as a professional software engineer. At universities, it usually takes more than one semesters two fully cover all the essential topics related to networking, something that I missed as I did not study computer science for my undergraduate studies. Now that I am working on infrastructure system, the need to fill up this gap of knowledge became increasingly important. I heard that “Computer Networking: A Top-Down Approach” by James F.Kurose and Keith W.Ross is one of the best networking books out there, thus I will be summarizing the core ideas that are relevant to me, and adding my thoughts to it in the next few blog posts.
Application Layer
The author goes over the 7 layers of Open Systems Interconnection (OSI) model, which describes the layers that computers use to communicate over a network. Each layers are explained in a reverse order that is more intuitive to understand.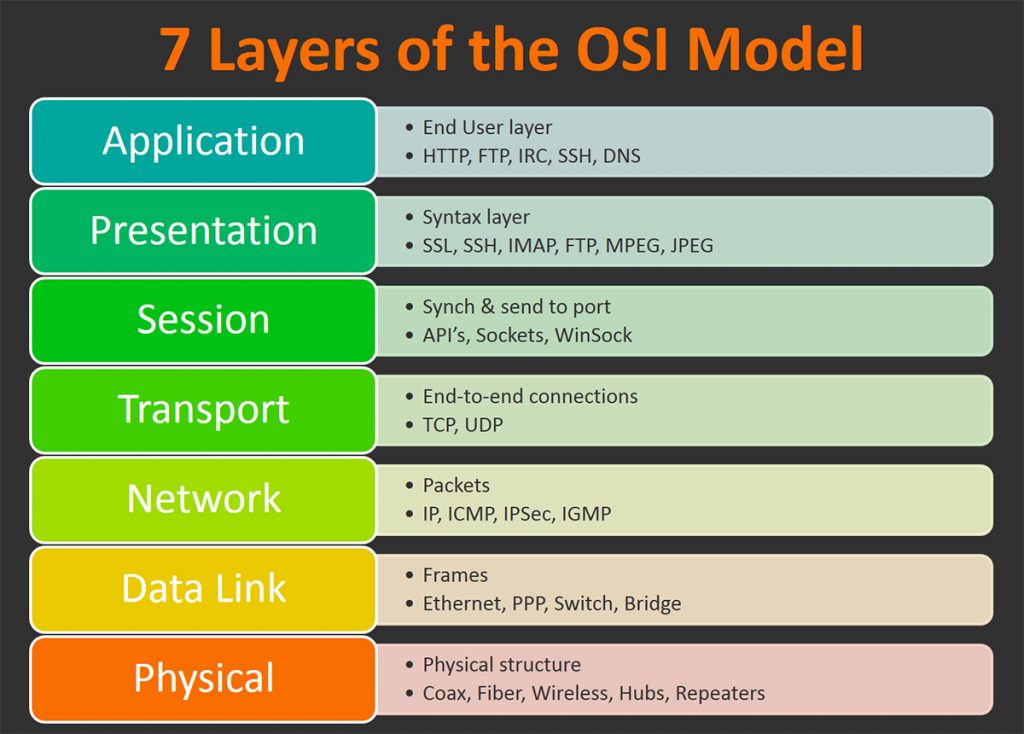
The first layer of the OSI model is the Application Layer, which is the end-user layer that most of the people interact with, such as browser programs running in the user’s host (desktop, laptop, tablet, phone), streaming contents from Netflix servers. When you are writing applications in languages like C, Java and Python, you just need to consider how applications talk to the network, and you never really have to consider how it would communicate within routers and other lower layers down the line. So naturally, whether than considering the entire 7 layers of the OSI model, application developers can solely focus on the application architecture.
Client-server architecture
The most typical application architecture would be the client-server architecture, such as Web, FTP, e-mail, and etc. Clients would request information, and when the web server receives the requests, it would respond by sending requested object to the client host. Because the server has a fixed, well-known address, and because the server is always on, a client can always contact the server by sending a request packet to the server’s IP address. Often in a client-server application, a single-server host is incapable of keeping up with all the requests from clients, so we have data center that hosts large number of application hosts, forming a collection of powerful virtual server.
P2P Architecture
In client-server architecture, a client would not directly interact with another client. However, in peer to peer (P2P) architecture, it is the opposite. There are minimal (or no) reliance on dedicated servers, and instead, peers (desktop and laptops controlled by users) talk to each other to exchange information, where the most typical example is the Torrent.
Communication Interface and Transport Protocol
Applications on either server or client is referred to as processes, and each processes have communication sockets (interface) that acts as a bridge b/w Application layer and Transport layer.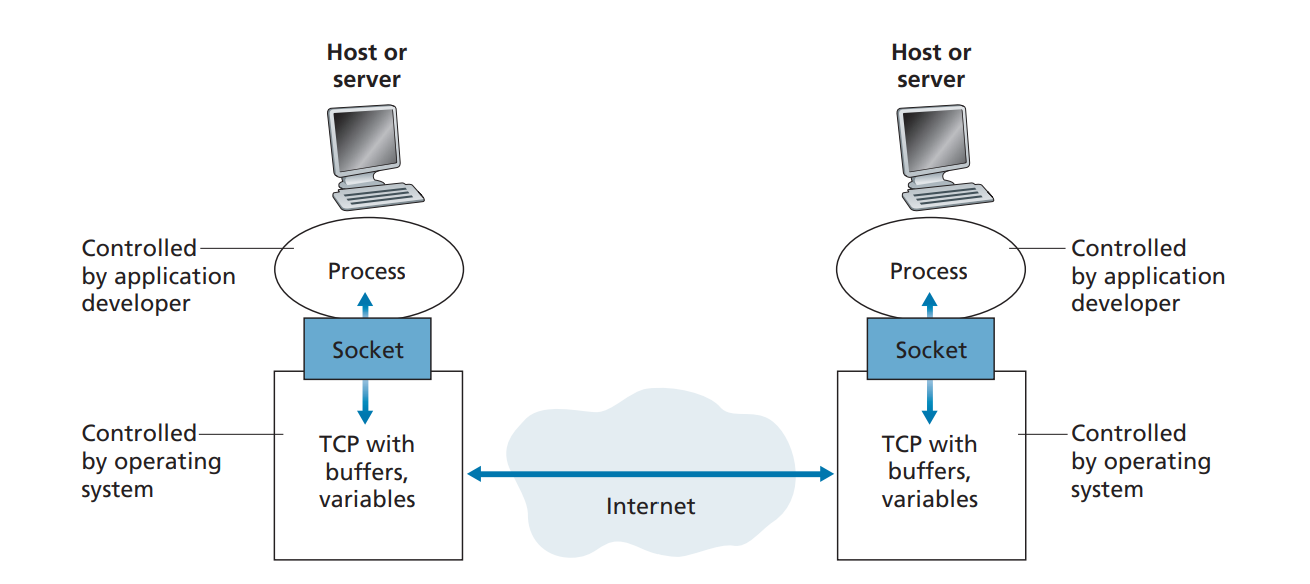
This socket is referred to as Application Programming Interface (API). The application developer has control of everything on the application-layer side of the socket but has little control of the transport-layer side of the socket. The only control that the application developer has on the transport layer side is:
- the choice of transport protocol
- transport-layer parameters such as maximum buffer and maximum segment sizes
The sockets are often depicted as the Session layer in the OSI model.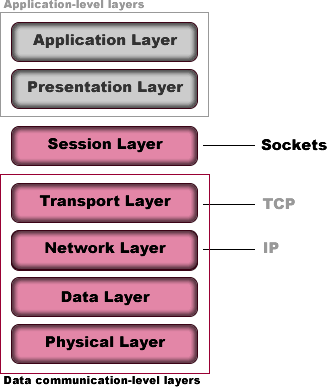
Each transport protocol has its own pros and cons. For example, there is Transmission control protocol (TCP) and User datagram protocol (UDP). For sensitive data that cares more about data loss, TCP protocol will be used. For interactive experience, UDP protocol will be typically used. The two protocols are often called UDP/IP or TCP/IP since they run on top of IP.
TCP Services (Transport layer protocol)
There are only two types of protocol in the Transport layer: TCP and UDP, and let’s start with TCP.
TCP service model includes a connection-oriented service and a reliable data transfer service. This is where the famous 3-way handshake comes in. TCP has the client and server exchange transport layer control information with each other before the application-level messages begin to flow. This is like building a concrete bridge of connection before exchanging any information.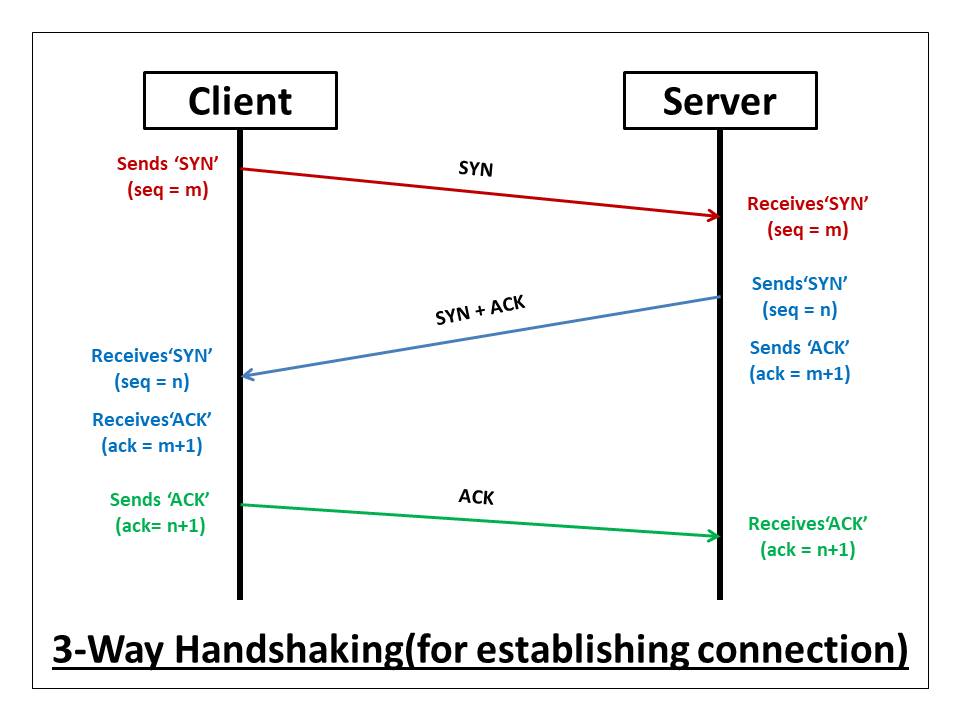
Because we have a TCP connection b/w server and host, we can have reliable stream of data. The packets data in bytes passed through socket can assure that messages arrive in correct order via TCP connection, with no missing or duplicate bytes. TCP also has traffic control system so that it does not overload network bandwidth.
Because TCP does not provide any encrpytion, a more secure version that uses TLS (Transport Layer Security) exists on top of TCP, providing encrpytion, data integrity, and end-point authentication.
UDP Services (Transport layer protocol)
UDP, on the other hand, is a lightweight transport protocol, which does not require any handshake or connections established before processes exchange information. Thus UDP does not guarantee that message will safely reach the other end, but it can pump data over to the other side in any rate it pleases, making it ideal for cases like live-streaming where being live matters more than anything else.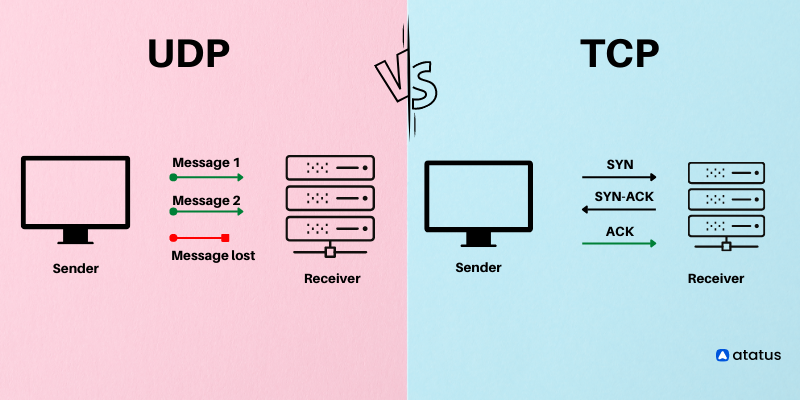
HTTP (Application Layer Protocol)
Messages generated by applications go through the session layer (sockets) and reach the transport layer. Application layer protocols define how these messages (requests, responses) get structured. The Web’s application-layer protocol, HyperText Transfer Protocol (HTTP), for example, defines the format and sequence of messages exchanged between browser and Web server.
HTTP defines how Web clients request Web pages from Web servers and how servers transfer Web pages to clients. The browser is always the entity initiating the request. It is never the server. To display a Web page, for instance, the browser sends an original request to fetch the HTML document that represents the page. When the server returns the requested object, the client side parses this file, making additional requests corresponding to execution scripts, layout information (CSS) to display, and sub-resources contained within the page (usually images and videos). The Web browser then combines these resources to present the complete document, the Web page.
HTTP uses TCP as its underlying transport protocol, The HTTP client first initiates a TCP connection with the server. Once TCP connection is established, client packages requests with HTTP protocol, shoots it over the socket interface, which goes through the TCP layer and eventually reaches the server over the network. Server sends back the response in this manner. HTTP/1 and HTTP/2 protocols are still actively used, by HTTP/3, which provides faster experience, has also been approved in 2022.
I won’t talk about the HTTP/3 here, as it’s not the official standard yet.
HTTP Request Message
A request message will look something like this.
GET /somedir/page.html HTTP/1.1
Host: www.someschool.edu
Connection: close
User-agent: Mozilla/5.0
Accept-language: fr
Most HTTP request will start with request lines, that contains methods like GET, from the HOST, but obviously there are other methods like POST, HEAD, PUT, DELETE. The part CLOSE talks about persistent vs none-persistent connection, which is covered in the section below.
HTTP Response Message
A response will look something like this.
HTTP/1.1 200 OK
Connection: close
Date: Tue, 18 Aug 2015 15:44:04 GMT
Server: Apache/2.2.3 (CentOS)
Last-Modified: Tue, 18 Aug 2015 15:11:03 GMT
Content-Length: 6821
Content-Type: text/html
Here, we have:
Statusmessage that tells you if server was able to respond to request correctly (200 is success). 404, 400, 505 are common error codes.Headerlines that have extra detailsContentwhich is the entity body that contains the data that was requested.
States, cookies, and caching
Another important thing to understand is that HTTP protocols are stateless. If a particular client asks for the same object twice in a period of a few seconds, the server does not respond by saying that it just served the object to the client; instead, the server resends the object, as it has completely forgotten what it did earlier. This makes no need to maintain complicated session b/w the client and server, and makes it much more scalable.
However, websites need to be able to identify who the user is even if it’s stateless, and this is often acheived with cookies, which allow sites to keep track of users. When a user makes request, it will assign unique ID to the clients browser, so that this ID is passed to the header section of the requests. Activities conducted by the client (associated with the cookie) will be saved to the application’s database, giving responses more relevant to the user.
And there is the concept of Caching. Requests for images and other heavier data is expensive. If the data have to be fetched from server (or client) again everytime, it would be very inefficient, so there is the middle proxy server (typically inside the client’s computer) that acts as a temporary storage.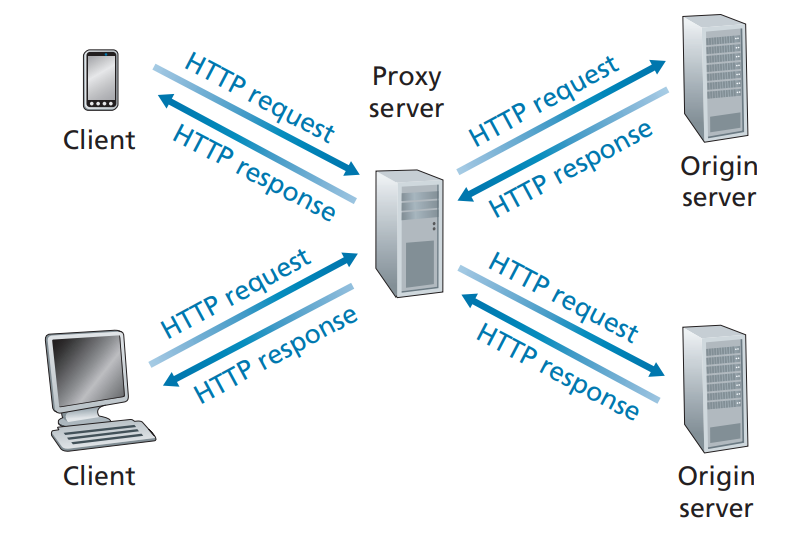
The author depicts Proxy Server in the context of web caching, where intermediary server (with IP address) satisfies the HTTP requests on behalf of the original Web Server. But you need to understand that Proxy Servers can be both server and a client, sending requests to server on behalf of the client, and responding on behalf of the server. On top of caching, it does:
- Filtering content
- Scan for malware
- Mask origin of the request
- Encrypt messages
- Handle authentication requests (serve as firewall)
- Prevent attackers from accessing private network
HTTP (Persistent vs None-Persistent)
When designing HTTP protocols that your application make, you can decide if you would like:
Persistent HTTP connections: Each request and response sent over same TCP connectionNon-persistent: Each request and response sent over seperate TCP connection (one request, one connection)
At first, you would wonder, you have already established TCP connection tunnel from server to client. Why bother creating multiple connections for every object you are trying to send and receive? Well, if you are sending very few requests, or requests frequency is very low, it actually becomes wasteful to keep connection open. Furthermore, non-Persistent Connection is more secure because after sending the data, the connection gets terminated and nothing can be shared thereafter.
But in most cases, non-persistent connections require greater CPU overhead, as there is no latency in subsequent requests. Moreover, resources may be kept occupied even when not needed and may not be available to others. Thus modern http connections have timeout to automatically close connections after inactivity.
DNS (Domain Name System)
The is another top application layer protocol.
Before setting up VPN according to this SSH article, it’s important to have a solid understanding of DNS. DNS is also application layer protocol. Like how humans can be identified by their names, social security numbers, and even email addresses, Internet hosts can be identified by hostnames instead of IP addresses, like google.com or facebook.com. DNS is nothing more than translating hostnames to IP addresses.
Apart from hostname translation, DNS can also do:
Aliasing: mapping hostnames to another. So that hostname A is mapped to hostname B, which point to IP address A.Load distribution: replicate servers to make popular sites load faster
DNS can make the interaction very slow, but similar to HTTP caching, IP addresses also get cached from nearby DNS servers.
The idea is simple, but how does DNS work exactly?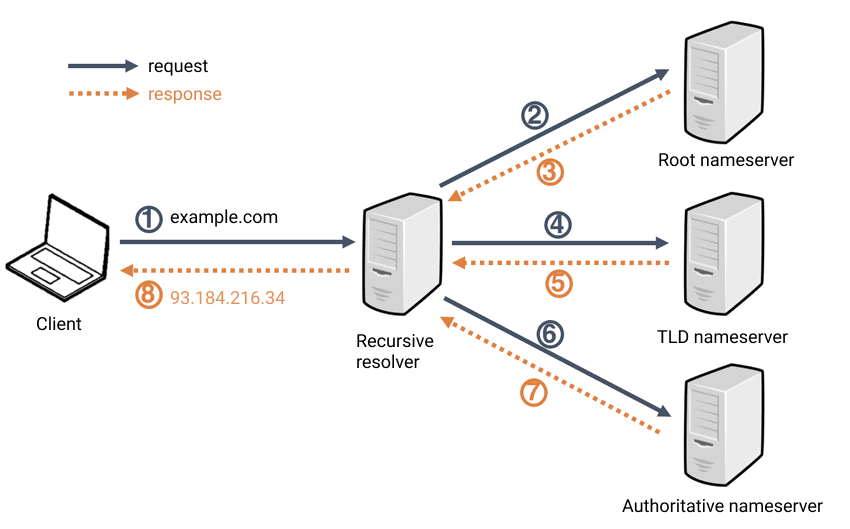
https://chophilip21.github.io/network_part1/
Here, HTTPS is the protocol, chophilip21.github.io is the domain, and network_part1 is the subdomain.
A typical interaction would be like the following:
- Client requests to access chophilip21.github.io. from internet browser
- Browser extracts host name from URL, and passes hostname to the client side of DNS application
- DNS client sends a UDP datagram query containing the hostname to a DNS server
- If the matching record exists, IP address is returned
- With the IP adddress, HTTP protocols start establishing TCP connections with the server on the IP address.
Input and output is very clear, but what actually happens under each step is actually quite complex. Look at the diagram above. There are three classes of DNS servers, in hierachy:
- A. Root DNS server: 13 root servers managed by 12 organizations. There are 1000 copies of root servers over the world.
- B. Top-level domain (TLD) server: For each root, top level domains like
com, org, net, edu, govhave TLD server clusters - C. Authoritative DNS server: final holder of the IP of the domain you are looking for (These the servers that actually stores type A, NS, CNAME records.)
- D. Local DNS server: Caches the IP address locally so that it doesn’t have to go through ABC all the time.
So it’s like search for library > search for the shelf > search for position of the book in the shelf. The data is recursively loaded back to the client from the bottom. Why only 13 root servers? It’s because of the limitation of IPv4 standard and the DNS infrastructure in each 512 byte UDP packet. For more info about this, refer to this post
Okay things are starting to make much more sense!
DNS Records and Messages
DNS resource records are saved as tuples that contains following values: \[\begin{align*} (Name, Value, Type, TTL) \end{align*}\]
TTLis the time to live of the resource record. it determines when a resource should be removed from a cache.- If
Type==A, then Value is IP address for the requested hostname (relay1.bar.foo.com, 145.37.93.126, A). Most standard calls for IPv4 - If
Type==AAAA, same idea of A record, but for IPv6 - If
Type==NS, then it points at authoritative DNS server that knows how to obtain the IP address for hosts in the domain - If
Type==CNAME, then it implies requests for aliasing, mapping hosts and the canonical name (foo.com, relay1.bar.foo.com, CNAME) - If
Type==MX, then it’s aliasing for emails.
Similar to how HTTP requests/responses are formatted, DNS requests and responses look like the following: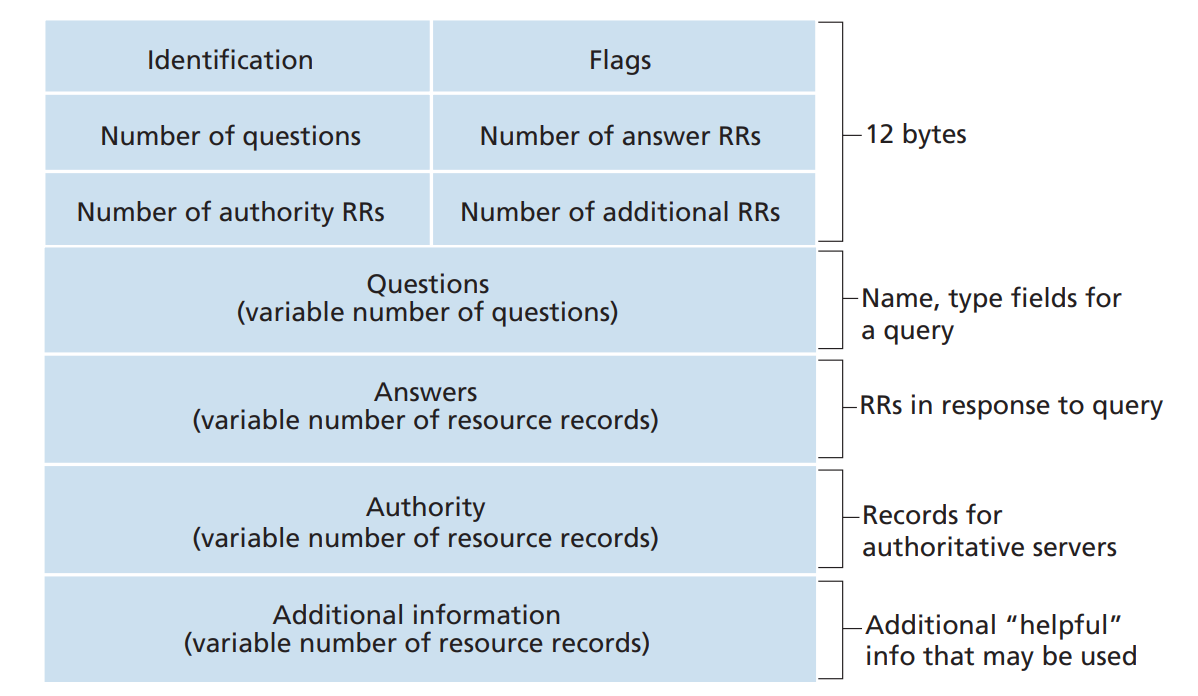
DNS Records Insertion and Propagation
This is the final section of DNS. How is different types of DNS record inserted? There are thousands of accredited registrars all across the globe. Some of the more popular ones include GoDaddy, Namecheap, HostGator, and DreamHost. They would not only host your content in a server, they would also register DNS records for you. After verifying your domain name is unique, it will enter the domain name into the DNS database.
You also need to register primary (dns1.networkutopia.com, 212.2.212.1) and secondary authoritative DNS servers (dns2.networkutopia.com, 212.212.212.2). A primary DNS server is the first point of contact for a browser, application or device that needs to translate a human-readable hostname into an IP address. The primary DNS server contains a DNS record that has the correct IP address for the hostname. If the primary DNS server is unavailable, the device contacts a secondary DNS server, containing a recent copy of the same DNS records.
So below is what will be registered.
(networkutopia.com, dns1.networkutopia.com, NS)
(networkutopia.com, dns2.networkutopia.com, NS)
(dns1.networkutopia.com, 212.212.212.1, A)
(dns2.networkutopia.com, 212.212.212.2, A)
From the bottom, it will go to TLD, and to Root server.
How does DNS propagation work?
Now the next question is, what happens if you want to keep the domain, but decide to switch the server location? The IP address will no longer remain the same. Because there is the Local DNS server caching mechanism, in order for the world to know this DNS change, it will take some time. The cache will expire based on TTL, and that is why it will take up to 72 hours for you to see the changes in the website.
Playing videos in the internet
The final section of the article is understanding the videos. The very first company that I joined as a software engineer, was specialized in processing video footages with ML algorithms. While I was mostly in charge of ML part of the software, I did also work on designing video players too, but I never seriously considered how they work online exactly. If you think about it, video is an immense amount of data, which displays 20-30 images per second. How on earth is it possible to stream HD videos (4 Mbps) and even 4K videos (10 Mbps) so smoothly? 2Mbps video that plays for 60 minutes will consume gigabytes of storage and traffic. So how does services like Youtube and Netflix displaying their contents to end-users?
To be able to stream videos, obviously the average internet throughput needs to be larger than the bit rate of the video. In the past, this was very difficult as our internet was much slower, so the video had to be either compressed to lower resolution in order to stream without stopping, or it had to be downloaded.
TCP based videos
And there is nothing different in the way that streaming works compared to other data that’s sent over the Internet. There is the video that lives in the server, and upon requests, audio and video data is broken down into data packets. In HTTP Streaming, the client establishes a TCP connection and the packets are sent over the network. When the packet reaches certain playable threshold, data will be decoded as buffered frames and played in an audio or video player (like Youtube) in the browser on the client device, while constantly requesting for the next portion of the data.
Naturally, there can be circumstances where the data has not been encoded in time while playing the video, where the video stops playing to wait for the next frames to be decoded. This is the buffering. To minimize the delays, which gets larger when packets need to pass multiple links and servers to arrive to the clients, most companies use Content Distribution Networ (CDN) that stores the copies of the videos in multiple geographical locations, and connects the clients to the nearest locations (instead of pulling from main server all the time). Furthermore, caching is actively used to lower the buffering and network consumption as much as possible.
UDP based videos
TCP connections make great sense for watching videos living in a server in a lossless fashion, but sometimes when you are watching live streams, speed and being live matters more than anything else. A few lost data packets do not matter that much, so UDP connection is used instead. Services like Youtube thus uses both UDP and TCP connections.